Following the illustrative example of Ridgway et al. 2012 [1], this demonstrates some basic ideas behind both the “hat” variance adjustment method, as well as threshold-free cluster enhancement (TFCE) [2] methods in mne-python.
This toy dataset consists of a 40 x 40 square with a “signal” present in the center (at pixel [20, 20]) with white noise added and a 5-pixel-SD normal smoothing kernel applied.
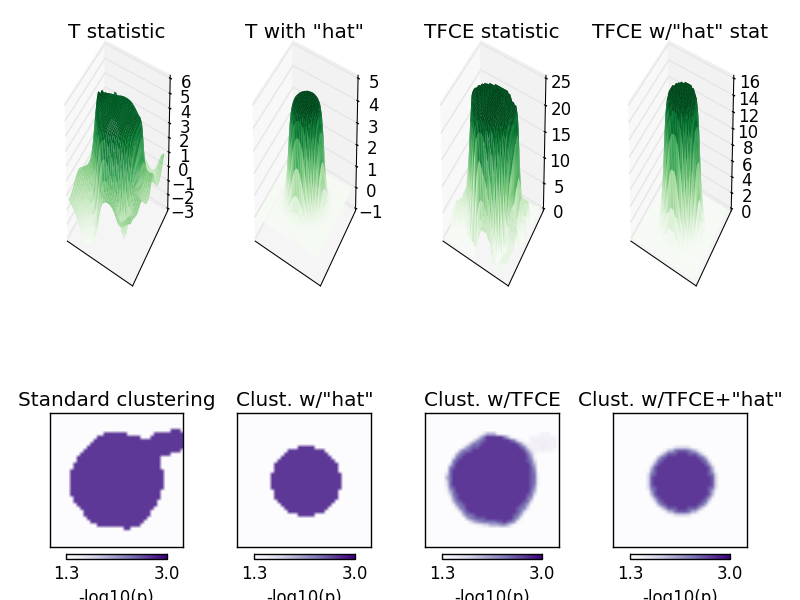
In the top row plot the T statistic over space, peaking toward the center. Note that it has peaky edges. Second, with the “hat” variance correction/regularization, the peak becomes correctly centered. Third, the TFCE approach also corrects for these edge artifacts. Fourth, the the two methods combined provide a tighter estimate, for better or worse.
Now considering multiple-comparisons corrected statistics on these variables, note that a non-cluster test (e.g., FDR or Bonferroni) would mis-localize the peak due to sharpness in the T statistic driven by low-variance pixels toward the edge of the plateau. Standard clustering (first plot in the second row) identifies the correct region, but the whole area must be declared significant, so no peak analysis can be done. Also, the peak is broad. In this method, all significances are family-wise error rate (FWER) corrected, and the method is non-parametric so assumptions of Gaussian data distributions (which do actually hold for this example) don’t need to be satisfied. Adding the “hat” technique tightens the estimate of significant activity (second plot). The TFCE approach (third plot) allows analyzing each significant point independently, but still has a broadened estimate. Note that this is also FWER corrected. Finally, combining the TFCE and “hat” methods tightens the area declared significant (again FWER corrected), and allows for evaluation of each point independently instead of as a single, broad cluster.
Note
This example does quite a bit of processing, so even on a fast machine it can take a few minutes to complete.
# Authors: Eric Larson <larson.eric.d@gmail.com>
# License: BSD (3-clause)
import numpy as np
from scipy import stats
from functools import partial
import matplotlib.pyplot as plt
# this changes hidden MPL vars:
from mpl_toolkits.mplot3d import Axes3D # noqa
from mne.stats import (spatio_temporal_cluster_1samp_test,
bonferroni_correction, ttest_1samp_no_p)
try:
from sklearn.feature_extraction.image import grid_to_graph
except ImportError:
from scikits.learn.feature_extraction.image import grid_to_graph
print(__doc__)
width = 40
n_subjects = 10
signal_mean = 100
signal_sd = 100
noise_sd = 0.01
gaussian_sd = 5
sigma = 1e-3 # sigma for the "hat" method
threshold = -stats.distributions.t.ppf(0.05, n_subjects - 1)
threshold_tfce = dict(start=0, step=0.2)
n_permutations = 1024 # number of clustering permutations (1024 for exact)
Make the connectivity matrix just next-neighbor spatially
n_src = width * width
connectivity = grid_to_graph(width, width)
# For each "subject", make a smoothed noisy signal with a centered peak
rng = np.random.RandomState(42)
X = noise_sd * rng.randn(n_subjects, width, width)
# Add a signal at the dead center
X[:, width // 2, width // 2] = signal_mean + rng.randn(n_subjects) * signal_sd
# Spatially smooth with a 2D Gaussian kernel
size = width // 2 - 1
gaussian = np.exp(-(np.arange(-size, size + 1) ** 2 / float(gaussian_sd ** 2)))
for si in range(X.shape[0]):
for ri in range(X.shape[1]):
X[si, ri, :] = np.convolve(X[si, ri, :], gaussian, 'same')
for ci in range(X.shape[2]):
X[si, :, ci] = np.convolve(X[si, :, ci], gaussian, 'same')
Note
X needs to be a multi-dimensional array of shape samples (subjects) x time x space, so we permute dimensions:
X = X.reshape((n_subjects, 1, n_src))
Now let’s do some clustering using the standard method.
Note
Not specifying a connectivity matrix implies grid-like connectivity, which we want here:
T_obs, clusters, p_values, H0 = \
spatio_temporal_cluster_1samp_test(X, n_jobs=1, threshold=threshold,
connectivity=connectivity,
tail=1, n_permutations=n_permutations)
# Let's put the cluster data in a readable format
ps = np.zeros(width * width)
for cl, p in zip(clusters, p_values):
ps[cl[1]] = -np.log10(p)
ps = ps.reshape((width, width))
T_obs = T_obs.reshape((width, width))
# To do a Bonferroni correction on these data is simple:
p = stats.distributions.t.sf(T_obs, n_subjects - 1)
p_bon = -np.log10(bonferroni_correction(p)[1])
# Now let's do some clustering using the standard method with "hat":
stat_fun = partial(ttest_1samp_no_p, sigma=sigma)
T_obs_hat, clusters, p_values, H0 = \
spatio_temporal_cluster_1samp_test(X, n_jobs=1, threshold=threshold,
connectivity=connectivity,
tail=1, n_permutations=n_permutations,
stat_fun=stat_fun, buffer_size=None)
# Let's put the cluster data in a readable format
ps_hat = np.zeros(width * width)
for cl, p in zip(clusters, p_values):
ps_hat[cl[1]] = -np.log10(p)
ps_hat = ps_hat.reshape((width, width))
T_obs_hat = T_obs_hat.reshape((width, width))
# Now the threshold-free cluster enhancement method (TFCE):
T_obs_tfce, clusters, p_values, H0 = \
spatio_temporal_cluster_1samp_test(X, n_jobs=1, threshold=threshold_tfce,
connectivity=connectivity,
tail=1, n_permutations=n_permutations)
T_obs_tfce = T_obs_tfce.reshape((width, width))
ps_tfce = -np.log10(p_values.reshape((width, width)))
# Now the TFCE with "hat" variance correction:
T_obs_tfce_hat, clusters, p_values, H0 = \
spatio_temporal_cluster_1samp_test(X, n_jobs=1, threshold=threshold_tfce,
connectivity=connectivity,
tail=1, n_permutations=n_permutations,
stat_fun=stat_fun, buffer_size=None)
T_obs_tfce_hat = T_obs_tfce_hat.reshape((width, width))
ps_tfce_hat = -np.log10(p_values.reshape((width, width)))
Out:
stat_fun(H1): min=-2.676791 max=5.182156
Running initial clustering
Found 1 clusters
Permuting ...
[ ] 0.09775 |
[. ] 3.12805 /
[.. ] 6.25611 -
[... ] 9.38416 \
[..... ] 12.51222 |
[...... ] 15.64027 /
[....... ] 18.76833 -
[........ ] 21.89638 \
[.......... ] 25.02444 |
[........... ] 28.15249 /
[............ ] 31.28055 -
[............. ] 34.40860 \
[............... ] 37.53666 |
[................ ] 40.66471 /
[................. ] 43.79277 -
[.................. ] 46.92082 \
[.................... ] 50.04888 |
[..................... ] 53.17693 /
[...................... ] 56.30499 -
[....................... ] 59.43304 \
[......................... ] 62.56109 |
[.......................... ] 65.68915 /
[........................... ] 68.81720 -
[............................ ] 71.94526 \
[.............................. ] 75.07331 |
[............................... ] 78.20137 /
[................................ ] 81.32942 -
[................................. ] 84.45748 \
[................................... ] 87.58553 |
[.................................... ] 90.71359 /
[..................................... ] 93.84164 -
[...................................... ] 96.96970 \ Computing cluster p-values
Done.
stat_fun(H1): min=-0.044294 max=4.600984
Running initial clustering
Found 1 clusters
Permuting ...
[ ] 0.09775 |
[. ] 3.12805 /
[.. ] 6.25611 -
[... ] 9.38416 \
[..... ] 12.51222 |
[...... ] 15.64027 /
[....... ] 18.76833 -
[........ ] 21.89638 \
[.......... ] 25.02444 |
[........... ] 28.15249 /
[............ ] 31.28055 -
[............. ] 34.40860 \
[............... ] 37.53666 |
[................ ] 40.66471 /
[................. ] 43.79277 -
[.................. ] 46.92082 \
[.................... ] 50.04888 |
[..................... ] 53.17693 /
[...................... ] 56.30499 -
[....................... ] 59.43304 \
[......................... ] 62.56109 |
[.......................... ] 65.68915 /
[........................... ] 68.81720 -
[............................ ] 71.94526 \
[.............................. ] 75.07331 |
[............................... ] 78.20137 /
[................................ ] 81.32942 -
[................................. ] 84.45748 \
[................................... ] 87.58553 |
[.................................... ] 90.71359 /
[..................................... ] 93.84164 -
[...................................... ] 96.96970 \ Computing cluster p-values
Done.
stat_fun(H1): min=-2.676791 max=5.182156
Running initial clustering
Using 26 thresholds from 0.00 to 5.00 for TFCE computation (h_power=2.00, e_power=0.50)
Found 1600 clusters
Permuting ...
[ ] 0.09775 |
[. ] 3.12805 /
[.. ] 6.25611 -
[... ] 9.38416 \
[..... ] 12.51222 |
[...... ] 15.64027 /
[....... ] 18.76833 -
[........ ] 21.89638 \
[.......... ] 25.02444 |
[........... ] 28.15249 /
[............ ] 31.28055 -
[............. ] 34.40860 \
[............... ] 37.53666 |
[................ ] 40.66471 /
[................. ] 43.79277 -
[.................. ] 46.92082 \
[.................... ] 50.04888 |
[..................... ] 53.17693 /
[...................... ] 56.30499 -
[....................... ] 59.43304 \
[......................... ] 62.56109 |
[.......................... ] 65.68915 /
[........................... ] 68.81720 -
[............................ ] 71.94526 \
[.............................. ] 75.07331 |
[............................... ] 78.20137 /
[................................ ] 81.32942 -
[................................. ] 84.45748 \
[................................... ] 87.58553 |
[.................................... ] 90.71359 /
[..................................... ] 93.84164 -
[...................................... ] 96.96970 \ Computing cluster p-values
Done.
stat_fun(H1): min=-0.044294 max=4.600984
Running initial clustering
Using 24 thresholds from 0.00 to 4.60 for TFCE computation (h_power=2.00, e_power=0.50)
Found 1600 clusters
Permuting ...
[ ] 0.09775 |
[. ] 3.12805 /
[.. ] 6.25611 -
[... ] 9.38416 \
[..... ] 12.51222 |
[...... ] 15.64027 /
[....... ] 18.76833 -
[........ ] 21.89638 \
[.......... ] 25.02444 |
[........... ] 28.15249 /
[............ ] 31.28055 -
[............. ] 34.40860 \
[............... ] 37.53666 |
[................ ] 40.66471 /
[................. ] 43.79277 -
[.................. ] 46.92082 \
[.................... ] 50.04888 |
[..................... ] 53.17693 /
[...................... ] 56.30499 -
[....................... ] 59.43304 \
[......................... ] 62.56109 |
[.......................... ] 65.68915 /
[........................... ] 68.81720 -
[............................ ] 71.94526 \
[.............................. ] 75.07331 |
[............................... ] 78.20137 /
[................................ ] 81.32942 -
[................................. ] 84.45748 \
[................................... ] 87.58553 |
[.................................... ] 90.71359 /
[..................................... ] 93.84164 -
[...................................... ] 96.96970 \ Computing cluster p-values
Done.
fig = plt.figure(facecolor='w')
x, y = np.mgrid[0:width, 0:width]
kwargs = dict(rstride=1, cstride=1, linewidth=0, cmap='Greens')
Ts = [T_obs, T_obs_hat, T_obs_tfce, T_obs_tfce_hat]
titles = ['T statistic', 'T with "hat"', 'TFCE statistic', 'TFCE w/"hat" stat']
for ii, (t, title) in enumerate(zip(Ts, titles)):
ax = fig.add_subplot(2, 4, ii + 1, projection='3d')
ax.plot_surface(x, y, t, **kwargs)
ax.set_xticks([])
ax.set_yticks([])
ax.set_title(title)
p_lims = [1.3, -np.log10(1.0 / n_permutations)]
pvals = [ps, ps_hat, ps_tfce, ps_tfce_hat]
titles = ['Standard clustering', 'Clust. w/"hat"',
'Clust. w/TFCE', 'Clust. w/TFCE+"hat"']
axs = []
for ii, (p, title) in enumerate(zip(pvals, titles)):
ax = fig.add_subplot(2, 4, 5 + ii)
plt.imshow(p, cmap='Purples', vmin=p_lims[0], vmax=p_lims[1])
ax.set_xticks([])
ax.set_yticks([])
ax.set_title(title)
axs.append(ax)
plt.tight_layout()
for ax in axs:
cbar = plt.colorbar(ax=ax, shrink=0.75, orientation='horizontal',
fraction=0.1, pad=0.025)
cbar.set_label('-log10(p)')
cbar.set_ticks(p_lims)
cbar.set_ticklabels(['%0.1f' % p for p in p_lims])
plt.show()
| [1] | Ridgway et al. 2012, “The problem of low variance voxels in statistical parametric mapping; a new hat avoids a ‘haircut’”, NeuroImage. 2012 Feb 1;59(3):2131-41. |
| [2] | Smith and Nichols 2009, “Threshold-free cluster enhancement: addressing problems of smoothing, threshold dependence, and localisation in cluster inference”, NeuroImage 44 (2009) 83-98. |
Total running time of the script: ( 2 minutes 8.866 seconds)