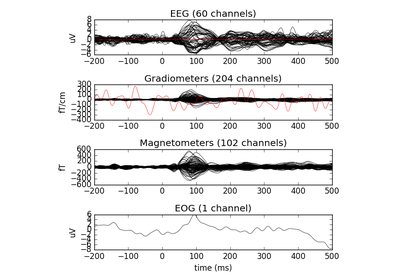
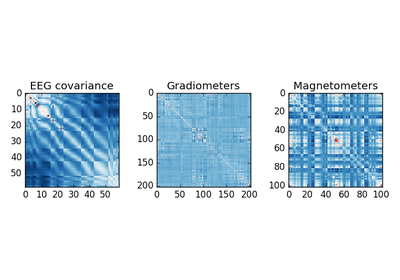
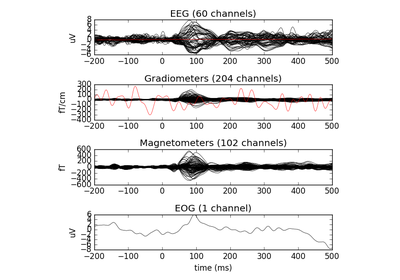
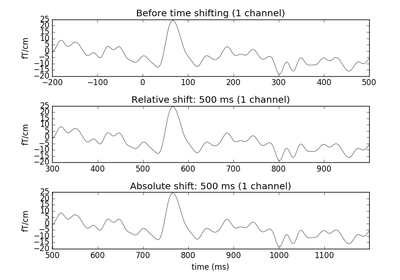
fname : string
The file name, which should end with -ave.fif or -ave.fif.gz.
condition : int or str | list of int or str | None
The index or list of indices of the evoked dataset to read. FIF files
can contain multiple datasets. If None, all datasets are returned as a
list.
baseline : None (default) or tuple of length 2
The time interval to apply baseline correction. If None do not apply
it. If baseline is (a, b) the interval is between “a (s)” and “b (s)”.
If a is None the beginning of the data is used and if b is None then b
is set to the end of the interval. If baseline is equal to (None, None)
all the time interval is used. Correction is applied by computing mean
of the baseline period and subtracting it from the data. The baseline
(a, b) includes both endpoints, i.e. all timepoints t such that
a <= t <= b.
kind : str
Either ‘average’ or ‘standard_error’, the type of data to read.
proj : bool
If False, available projectors won’t be applied to the data.
allow_maxshield : bool | str (default False)
If True, allow loading of data that has been recorded with internal
active compensation (MaxShield). Data recorded with MaxShield should
generally not be loaded directly, but should first be processed using
SSS/tSSS to remove the compensation signals that may also affect brain
activity. Can also be “yes” to load without eliciting a warning.
verbose : bool, str, int, or None
|